
「アカウントはもらったけど、どこから触ればいいか分からない」
「SQLは書けるけど、BIツールの画面構成がよく分からない」
「同僚に聞きづらく、とりあえずNew Queryを開いたまま放置している」
——BIツールを日次で使うデータ分析チームの支援現場で、こうした声が圧倒的に多いです。
Redash(リダッシュ)は、SQLでデータを取得し、グラフ・ダッシュボードに可視化できるオープンソースのBIツールです。
Tableau・LookerのようなGUI主体のBIとは異なり、SQLを書ける人が直接データソースに繋がる点が最大の特徴です。
GUIの制約を受けにくく、JOIN・ウィンドウ関数・集計ロジックを自由に組めるため、SQLを書ける人が1人でもチームにいれば、高品質なダッシュボードを内製で構築できるツールと言えます。
本記事では、数百名のユーザー・数千本のクエリ・数百枚のダッシュボードが稼働するBIツール環境の運用知見をもとに、初めての人が最短30分で第一関門を突破し、その後の運用でつまずかないための手順を体系的に解説します。

本記事のターゲット
- RedashなどのSQL系BIツールを初めて使うデータアナリスト・マーケター・エンジニアの方
- SQLは書けるが、Query・Dashboard・Snippetの違いを整理したい方
- 命名規則・パーティション・個人情報の運用ルールまで含めて学びたい方
全体像:Redash入門の5ステップ
本記事で扱うRedash入門の流れは、次の5ステップです。
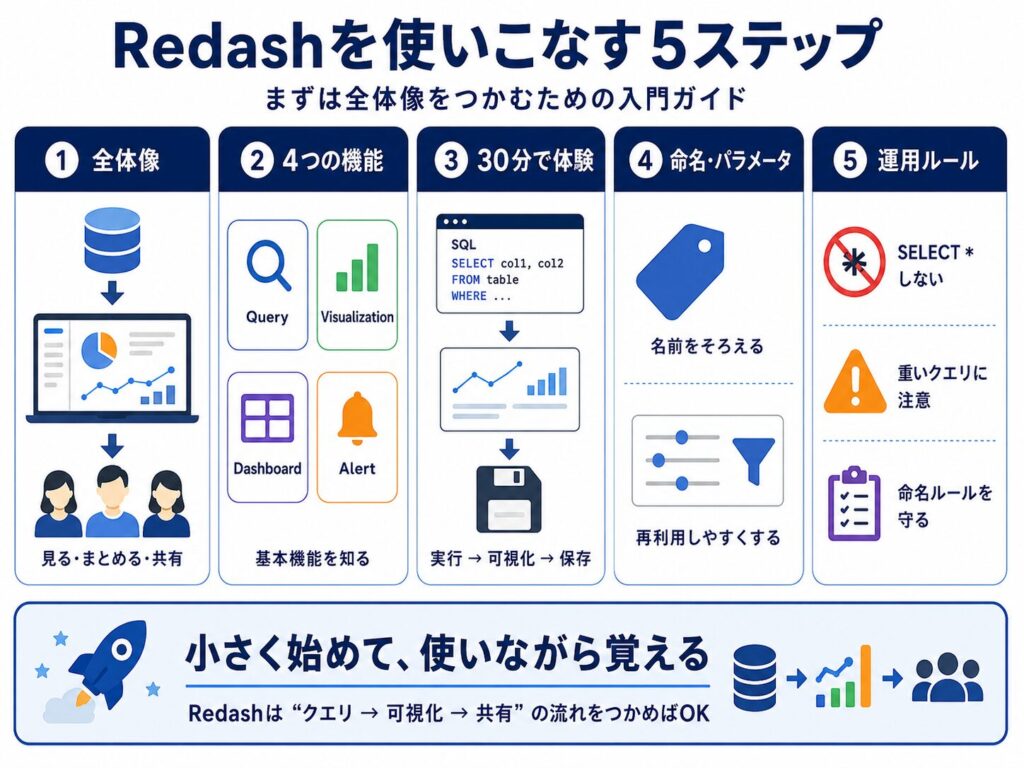
| ステップ | 主なアウトプット | 目安時間 |
|---|---|---|
| Step1 全体像 | Redashの位置づけ、向いているチーム | 5分 |
| Step2 主要機能 | 4機能+Snippet/Parameterの役割 | 10分 |
| Step3 ロードマップ | 初回クエリの実行・可視化・保存 | 30分 |
| Step4 命名・パラメータ | 命名フォーマット、パラメータクエリ | 30分〜 |
| Step5 運用ルール | NG事項チェックリスト | 継続 |
Step1:Redashの全体像——オープンソースBIツールの代表格
Redashが選ばれる理由
| 理由 | 内容 |
|---|---|
| SQLで自由度が高い | GUIに縛られず、複雑な集計・横断分析も可能。SQLを書ける人が1人いれば、チーム全体のダッシュボード品質を底上げできる |
| データソースが豊富 | Athena/MySQL/PostgreSQL/BigQuery/Snowflakeなど50種以上 |
| ダッシュボード共有が簡単 | URL1つでチーム共有 |
| オープンソースで無料 | 自社環境にインストール可能。ライセンス費がかからないため、Tableau等の有償BIと比べて費用面の優位性が大きい |
| パラメータ機能 | 1本のクエリを多目的に使い回せる |
Tableauとの費用感の違い(目安)
| 観点 | Redash | Tableau(有償BIの例) |
|---|---|---|
| ソフトウェア費用 | オープンソース版は無料(自社ホスト) | ユーザー数・エディションに応じたライセンス費 |
| 必要なスキル | SQLが書けると高品質な分析が可能 | GUI操作中心でも可視化しやすい |
| 向くチーム | SQL人材がいる・内製したい | GUIだけで回したい・予算に余裕がある |
Redash本体は無料でも、接続先がクエリ実行課金型(AWS Athena 等)の場合は、実行のたびにスキャン量に応じたデータ処理費用が発生します。BIツールのライセンス費を抑えても、SQLの書き方次第でクラウド費用は膨らみ得る
——Step3・Step5で触れるパーティション設計が重要です。
生成AI時代のSQL作成——ハードルは下がったが、品質チェックは必須
最近は生成AIの進化により、SQLを一から書くハードルは確実に下がりつつあります。
特に次の組み合わせは実務で有効です。
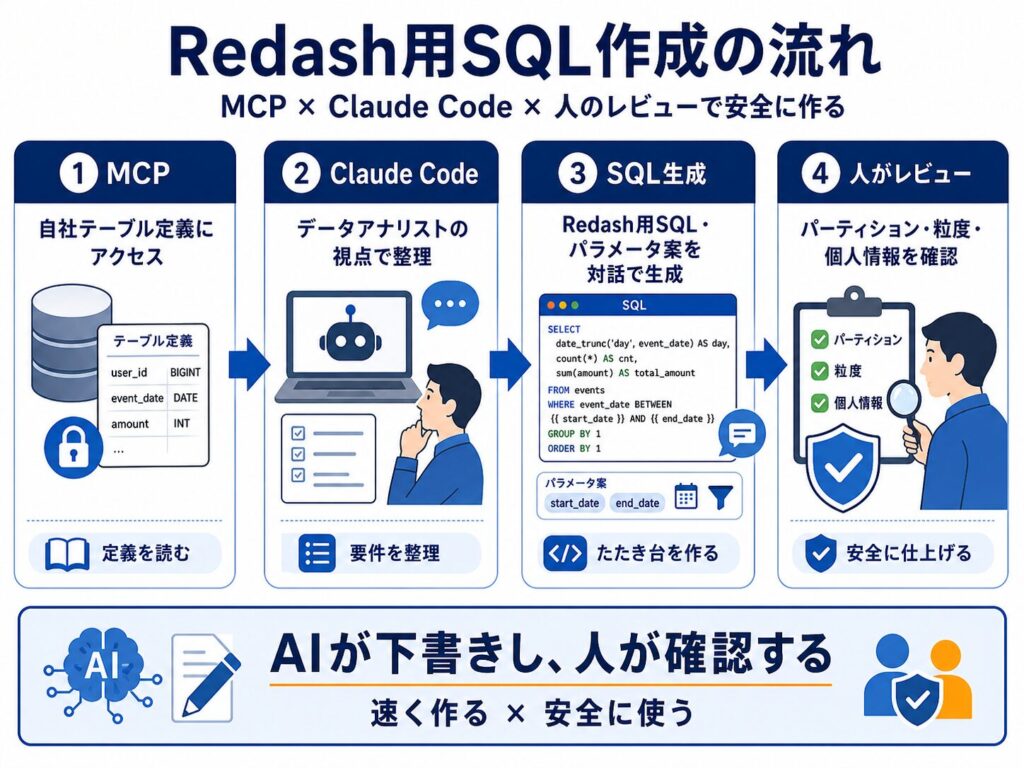
Claude Code にテーブル定義(Glue Catalog 等)へ接続するMCPを組み合わせれば、「このKPIを月次で見たい」と伝えるだけで叩き台SQLが得られます。
ただし、AI生成SQLはパーティション漏れ・フルスキャン・誤ったJOINを含むことがあるため、必ず人間が品質チェックしてから本番保存してください。
AIは「下書き担当」、最終責任は運用者
——この線引きが安全な使い方です。
ただこれまでのSQLを書くハードルが低くなった上に、作業効率としても体感10倍ほどになった体感です。
Redashが向いているチーム
- SQLを書けるメンバーが1人以上いる(複数いればより理想的)
- データソースが複数(横断分析したい)
- ライセンス費を抑えつつ、内製で運用したい
逆に、SQLを書けないメンバーだけで回す必要がある場合は、Tableau/Looker等のGUI主体BIの方が適しています。
ただし生成AI+MCPでSQLの叩き台を作り、レビューできる体制さえあれば、Redashの導入ハードルは以前よりかなり下がっていると言えます。
Step2:主要4機能の理解
Redashは Query / Visualization / Dashboard / Alert の4つの機能を押さえれば、操作で迷うことはほとんどなくなります。
以下、各機能の役割と画面イメージを示します。
| 用語 | 役割 | ひとことで |
|---|---|---|
| Query | SQL本体 | 計算の素 |
| Visualization | グラフ/表 | 見せ方 |
| Dashboard | 集約画面 | 共有の単位 |
| Snippet | SQL断片 | 使い回し |
| Alert | 通知 | 異常検知 |
| Parameter | 変数({{ }}) | 入力切替 |
Query(クエリ)——SQLでデータを取る
SQLエディタにクエリを書き、Execute でデータソースへ問い合わせます。
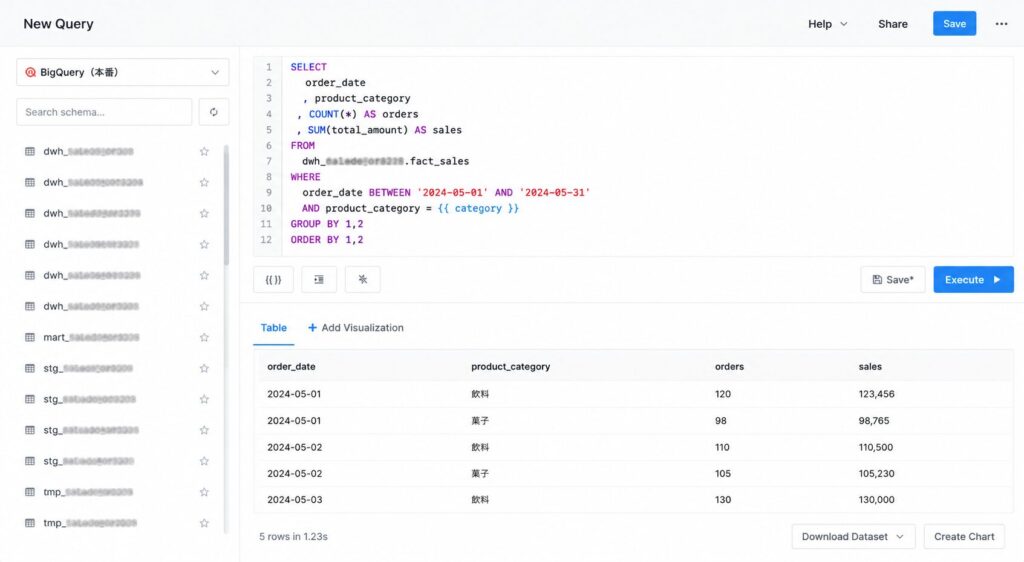
Redashの価値の中心であり、ここで集計ロジック・パーティション条件・パラメータを定義します。
右上「:」から「Fork」を選択すると、「Copy of」というプレフィックスがついてクエリをコピーすることもできます。
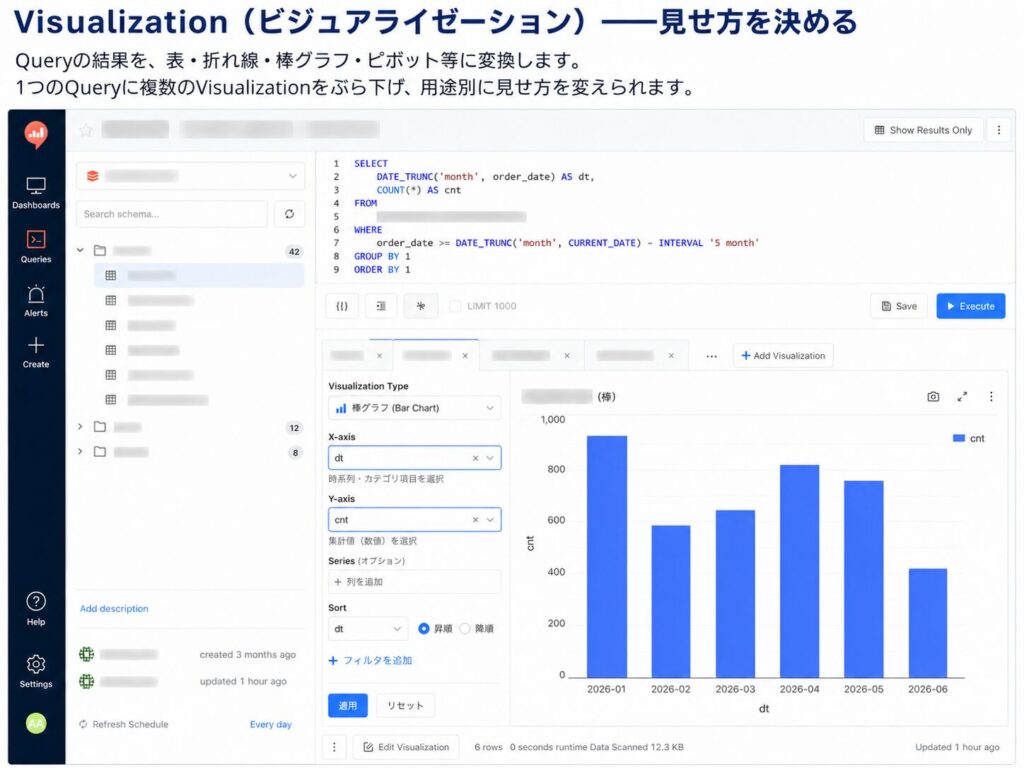
Visualization(ビジュアライゼーション)——見せ方を決める
Queryの結果を、表・折れ線・棒グラフ・ピボット等に変換します。
1つのQueryに複数のVisualizationをぶら下げ、用途別に見せ方を変えられます。
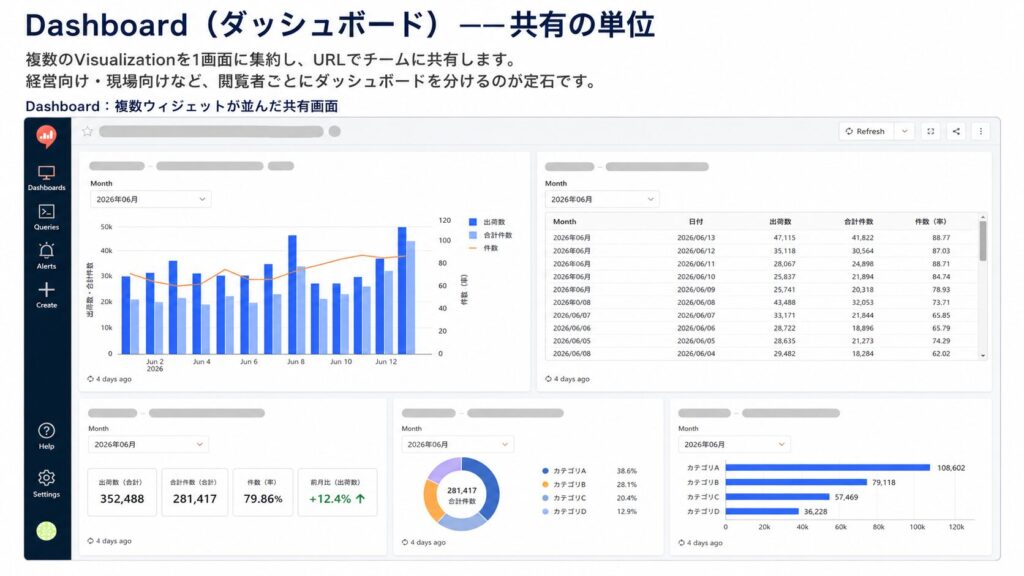
Dashboard(ダッシュボード)——共有の単位
複数のVisualizationを1画面に集約し、URLでチームに共有します。
経営向け・現場向けなど、閲覧者ごとにダッシュボードを分けるのが定石です。
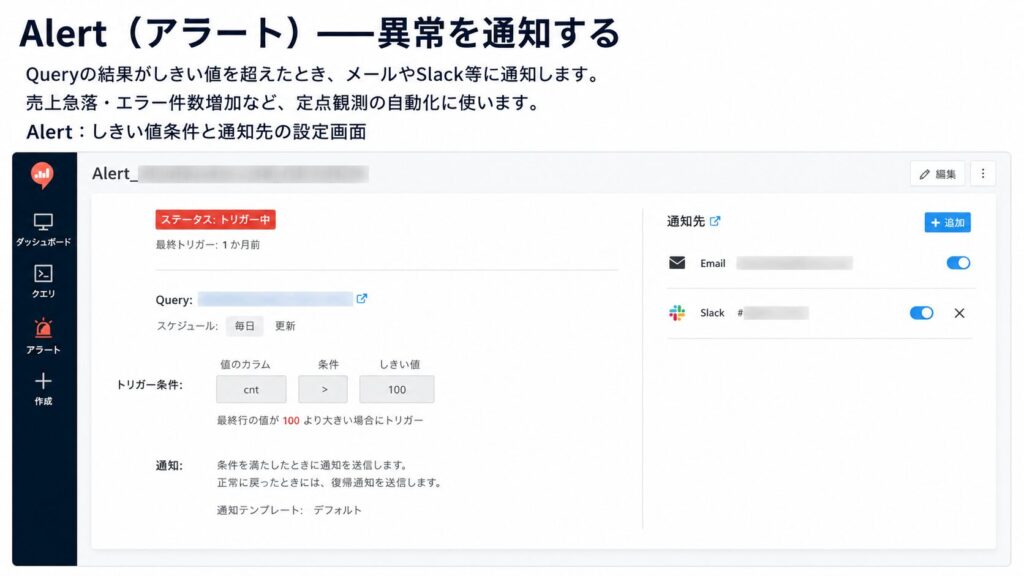
Alert(アラート)——異常を通知する
Queryの結果がしきい値を超えたとき、メールやSlack等に通知します。
売上急落・エラー件数増加など、定点観測の自動化に使います。
Step3:最初の30分ロードマップ
ステップ1(5分):ログインとデータソース確認
- BIツールにログイン
- 新規クエリ作成(Redashでは Create > New Query)を開く
- データソース選択で、分析対象(例:Athena)が選べることを確認
ステップ2(10分):最初のクエリを書く
いきなり大きなテーブルを SELECT * で叩くのは禁物です。
必ず日付パーティション(dt/ds)で範囲を絞りましょう。
またRedashには出力行数に制限があるため、limitをつけてまず出力してみましょう。
SELECT dt, count(*) AS cnt
FROM sales.order_log
WHERE dt BETWEEN date '2026-05-01' AND date '2026-05-31'
GROUP BY dt
ORDER BY dt
limit 100;Execute(実行)を押して結果が表に出れば、第一関門突破です。
クエリ課金型データソースの注意(Athena 等) Redashの実行ボタンを押すたびに、接続先でスキャン量に応じた課金が発生する場合があります。
開発中にパーティションなしの SELECT * を繰り返すと、BIツールは無料でもクラウド費用だけが膨らむ典型パターンです。
実行後は画面下部の Data scanned(スキャン量)を必ず確認し、数百MB〜数GBを超える場合はWHERE句を見直してください。
ステップ3(10分):可視化(グラフ化)
- 可視化を追加(Redashでは + Add Visualization)をクリック
- グラフタイプ(Chart)を選択
- X軸に
dt、Y軸にcntを指定 - Save
ステップ4(5分):保存と共有
- クエリに分かる名前を付ける(Step4参照)
- Save で保存
- ダッシュボードに追加して共有
Step4:命名・パラメータで使い回しやすくする
推奨命名フォーマット
[領域] 目的_対象_粒度
例:[SALES] 月次売上_カテゴリ別避けたい例:New Query、集計、test、Copy of ...(由来不明の複製)
パラメータクエリの基本
SELECT *
FROM sales.order_log
WHERE dt = date '{{yyyymmdd}}'
AND product_category = '{{product_category}}';| 型 | 使うケース |
|---|---|
| Text | 自由入力 |
| Date / Date Range | 日付(文字列だと事故りやすい) |
| Dropdown | 選択肢が決まっているもの |
ダッシュボード命名規約
d{NN}-kebab-case
例:d12-monthly-salesStep5:BIツールで「やってはいけない」6つのこと
| NG | 内容 | なぜダメか |
|---|---|---|
| NG1 | 生データのファイル出力(個別レコードのCSV共有は原則禁止) | 個人を特定できる行データが社外に流出するリスクがある。集計結果(件数・率)に留めるのが原則 |
| NG2 | パーティション指定なしのフルスキャン | Athena等ではスキャン量=課金に直結。意図しない高額請求と、クエリの極端な遅延を招く |
| NG3 | 本番テーブルへの直接書き込み | BIツールは参照(SELECT)専用が前提。誤ったUPDATE/DELETEで本番データを破壊する事故が起きうる。必要最低限の権限のみ付与する様にする |
| NG4 | 個人情報の無防備な共有 | ダッシュボードURLやCSVが社外に転送されると、個人情報保護法・社内規程違反になりうる |
| NG5 | 無題・下書きの放置 | New Query のまま放置すると、後から同じ分析を誰も再利用できず、組織のクエリ資産が死蔵・重複する |
| NG6 | 「Copy of」の連鎖(共通部分はSnippetへ) | ロジック修正時に何十本も直す羽目になり、バグとコスト(スキャン量)が雪だるま式に増える |
困ったらこの3つを自問:
- これは集計結果か?
- パーティションを切ったか?
- 個人情報を晒していないか?
まとめ:Redash入門の3つの要点
01 Query → Visualization → Dashboard の順で理解する
SQL本体・見せ方・共有単位の3層を押さえれば、画面操作で迷わない。
02 最初の1本はパーティション付きの小さなSELECTから
WHERE dt = ... と limit を必ず付け、名前を付けて保存するまでが入門のゴール。
03 命名・パーティション・個人情報の3つを軽視しない
便利なBIツールも、この3つを軽視するとすぐに事故る。
クエリ課金型のデータソースではパーティション漏れがそのまま費用増につながる。Snippetとパラメータで「Copy of」を減らす。
Redashはオープンソースで無料、SQLの柔軟性、生成AI+MCPによるSQL作成支援
——この3つが揃う今、内製BIの選択肢として非常に有力です。
まずは1本、パーティション付きのクエリを最後まで完成させて保存することから始めましょう。
最初の1本を最後まで仕上げた経験は、必ず次の10本につながります。
よくある質問
Redashのオープンソース版は自社ホストであればライセンス費はかかりません(Tableau等の有償BIと比べてソフトウェア費用面で優位です)。ただし「SQLが書けなくてもGUIだけで高品質な分析ができる」ツールではありません。ダッシュボードの閲覧・パラメータ変更はSQL不要ですが、クエリ作成・修正にはSQLが必要です。チームにSQLが書ける人が1人いれば、他メンバー向けのダッシュボードを内製できます。生成AI+MCPで叩き台を作り、レビューできる体制があれば、SQL未経験者でも「使う側」として始めやすくなっています。
最大の違いは「SQL中心か、GUI中心か」です。RedashはSQLでデータを取り、Visualizationで見せ方を決め、Dashboardで共有します。Tableauはドラッグ&ドropでも可視化しやすく、ライセンス費がかかります。RedashはJOIN・ウィンドウ関数など複雑な集計の自由度が高く、SQL人材がいる内製チーム向き。TableauはGUIだけで回したい・予算に余裕があるチーム向き、と整理すると選びやすいです。どちらも接続先がAthena等の課金型データソースなら、実行時のスキャン費用は別途発生します。
QueryはSQL本体(計算の素)、Visualizationはグラフ・表(見せ方)、Dashboardは複数のVisualizationを1画面に集めた共有単位です。SnippetはSQLの共通部分(日付フィルタやJOIN句など)を切り出して使い回す断片、Parameterは {{ }} で日付やカテゴリを差し替える変数です。覚える順番は Query → Visualization → Dashboard。AlertはQueryの結果がしきい値を超えたときに通知する機能です。初めて触る方は、まずQueryで1本実行し、Visualizationを1つ付け、Dashboardに載せる——この3ステップまでを30分のゴールにすると迷いません。
まず次の4点を確認してください。(1)パーティション列(dt / ds)の日付範囲が正しいか、(2)Parameterのデフォルト値が意図どおりか、(3)WHERE句の型キャスト(文字列 vs date型)で行が落ちていないか、(4)データ供給側(ETL・パーティション追加)に障害がないか。昨日まで動いていたクエリなら、SQLロジックより「対象日のデータがまだ入っていない」「パーティション未追加」が原因であることが多いです。Athenaの場合は MSCK REPAIR TABLE でパーティション整合性も確認します。
Redash本体は無料でも、Athena等は実行のたびにスキャン量に応じて課金されます。改善の優先順位は(1)WHERE dt = ... などパーティションで範囲を絞る、(2)SELECT * をやめ必要列だけ取得、(3)JOIN前に各テーブルを集計してから結合、(4)Execute後の Data scanned を確認し数百MB〜数GB超ならSQLを見直す、です。開発中に同じ重いクエリを何度もExecuteすると、BIツールは無料でもクラウド費用だけ膨らむ典型パターンです。まず WHERE dt = ... LIMIT 10 の最小再現から始めてください。
既存のQueryに対し、結果がしきい値を超えた(または下回った)ときにメール・Slack等へ通知する機能です。例:日次エラー件数が100を超えたらSlackへ、売上が前週比50%以下ならメールへ。Query画面からAlertを作成し、実行スケジュール(例:毎朝9時)と条件を設定します。注意点は、Alert用QueryもExecuteのたびにスキャン課金が発生すること、および個人情報を含む生データを通知本文に載せないことです。異常検知の「定点観測」に向いています。
叩き台作成には有効ですが、品質チェックなしの本番保存は避けてください。自社テーブル定義に接続するMCPとClaude Codeを組み合わせると、「月次売上をカテゴリ別に見たい」といった自然言語からRedash用SQLが得られます。一方、AI生成SQLにはパーティション漏れ・フルスキャン・誤JOIN・個人情報列の混入が起き得ます。AIは「下書き担当」、Execute前に人間がパーティション・集計粒度・PIIをレビューする——この線引きが安全な使い方です。SQL初心者の方こそ、Step5のNG事項チェックリストとセットで使うことをおすすめします。
数百名・数千クエリ規模になると、命名なしでは検索・再利用・権限管理が破綻します。最低限、[領域] 目的_対象_粒度 形式の命名、New Query 放置の禁止、共通SQLはSnippet化、個別レコードのCSV出力禁止をチームルールにしてください。個人情報(氏名・メール・電話等)は集計結果に留め、ダッシュボードURLの社外共有も規程に従います。Redashは使えば使うほど便利ですが、パーティション・命名・PIIの3つを軽視すると、コスト増・情報漏洩・クエリ資産の死蔵が同時に起きます。Step4・Step5をチームで1ページにまとめて共有するのが現実解です。
