「先月のAthena請求が想定の数倍になっていた」
「ダッシュボードを開くたびに数百GBスキャンしている」
「クエリ自体は速いのに、料金明細を見て驚いた」
——BIツール・Athena環境を日次で使うデータ分析チームの支援現場で、こうした相談は後を絶ちません。
AWS Athenaの料金は、スキャンしたデータ量に比例します(2026年6月時点で5USD/TB)。
つまり「速く・安く」する答えは、ほぼ一点に集約されます。
読まなくていいデータを読まないこと。
本記事では、数千本のクエリ・数百枚のダッシュボード・数百名のユーザーが稼働するBIツール環境の運用知見をもとに、コストを90%以上削減するための実践手順を体系的に解説します。

本記事のターゲット
- Athenaの料金が想定より高いと感じているデータアナリスト・データエンジニアの方
- パーティション設計・SQL最適化でスキャン量を削減したい方
- ダッシュボード自動更新の重いクエリを中間テーブル化したいBI担当の方
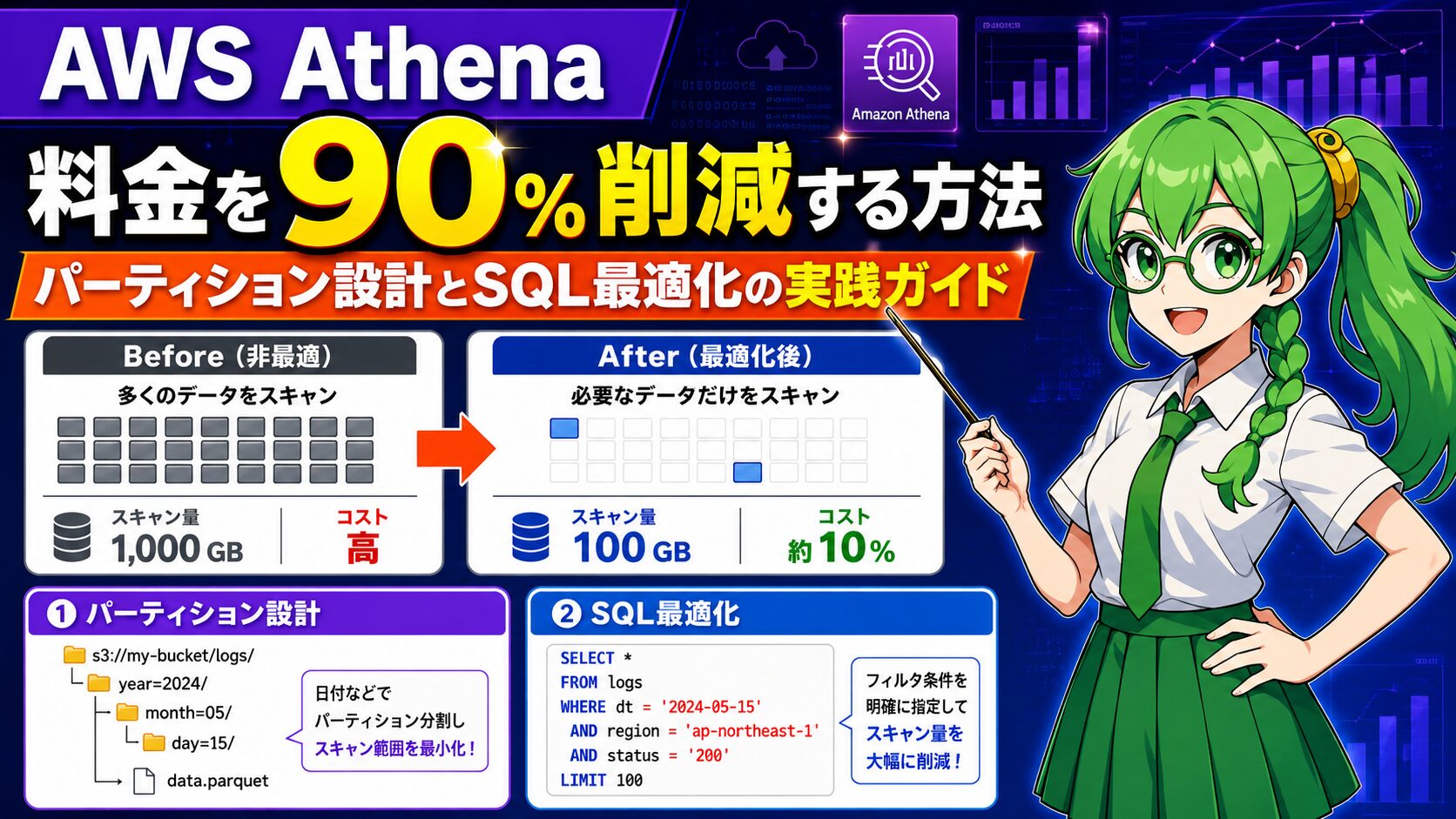
全体像:Athenaコスト最適化の5ステップ
本記事で扱うコスト削減の流れは、次の5ステップです。
| ステップ | 主なアウトプット | 削減効果 |
|---|---|---|
| Step1 原因把握 | フルスキャン・SELECT *・自動更新の特定 | — |
| Step2 パーティション | WHEREにdt/ds必須のルール | ★★★★★ |
| Step3 列絞り | 必要列のみSELECT | ★★★★ |
| Step4 書き方 | 関数NG回避、CTAS中間テーブル | ★★★★★ |
| Step5 モニタリング | 月次TOP10重いクエリリスト | ★★★ |
Step1:原因の把握——なぜAthenaの料金は急に高くなるのか
| 原因 | 起きていること | 影響度 |
|---|---|---|
| WHEREにパーティションがない | 数TB単位のテーブルをフルスキャン | ★★★★★ |
SELECT * の常用 | Parquetの列指向の利点を捨てている | ★★★★ |
| ダッシュボード自動更新 | 同じ重いクエリが日次で回り続ける | ★★★ |
実例:1クエリで数百GBスキャンしていた事例
日次更新のKPIダッシュボード(売上推移グラフ)が、毎朝1回の自動実行で数百GBをスキャンしていました。原因はSELECT *型クエリで、パーティションdtを加え必要列だけに絞った結果、スキャン量は数GB(約99%減)。月額換算でも数万円規模→数百円規模まで下がりました。
Step2:パーティション(dt/ds)でWHEREを切る
× パーティション指定なし
SELECT * FROM sales.order_log WHERE customer_id = 'C00001';
○ パーティションで範囲を限定
SELECT dt, customer_id, amount
FROM sales.order_log
WHERE dt BETWEEN date '2026-05-01' AND date '2026-05-31'
AND customer_id = 'C00001';| パーティション列 | 意味 | 用途 |
|---|---|---|
dt | 日次パーティション | 直近の詳細分析 |
ds | 断面パーティション | 期間比較・トレンド分析 |
Step3:SELECT * を避け、必要な列だけ取る
Parquet(列指向)では、SELECTする列だけがディスクから読み込まれます。
× 多数の列を全て読み込む(例:数十GBスキャン)
SELECT * FROM sales.customer_master WHERE dt = date '2026-06-01';
○ 必要な数列だけ(例:数GBスキャン)
SELECT customer_id, region, gender, signup_at
FROM sales.customer_master WHERE dt = date '2026-06-01';Step4:クエリの書き方——関数NG・LIMIT・中間テーブル化
パーティション列に関数をかけない
× パーティション枝刈りが効かない
WHERE year(dt) = 2026 AND month(dt) = 5
○ 範囲比較
WHERE dt BETWEEN date '2026-05-01' AND date '2026-05-31'探索フェーズは LIMIT で済ませる
SELECT * FROM sales.order_log
WHERE dt = date '2026-06-01'
LIMIT 100;重い集計は中間テーブル化
| 状況 | 中間テーブル化 |
|---|---|
| 同じ集計を1日10回以上叩く | ★★★★★(必須) |
| ダッシュボードで使う | ★★★★ |
| 1人が月1回だけ使う | ★(不要) |
CREATE TABLE sales.monthly_sales_summary
WITH (format = 'PARQUET', partitioned_by = ARRAY['ds']) AS
SELECT customer_id, product_category, sum(amount) AS total_amount,
date_format(date_trunc('month', dt), '%Y-%m-01') AS ds
FROM sales.order_log
WHERE dt >= date '2026-01-01'
GROUP BY customer_id, product_category, date_trunc('month', dt);Step5:スキャン量の見積もり・モニタリング
- Athenaクエリ履歴で1クエリごとの Data scanned (MB) を確認
- 月次でTOP10の重いクエリを抽出
- CloudWatchアラームで月額コストの閾値を設定
bytes_scanned_cutoff_per_queryで1クエリの上限を設ける
まとめ:Athenaコスト最適化の3つの要点
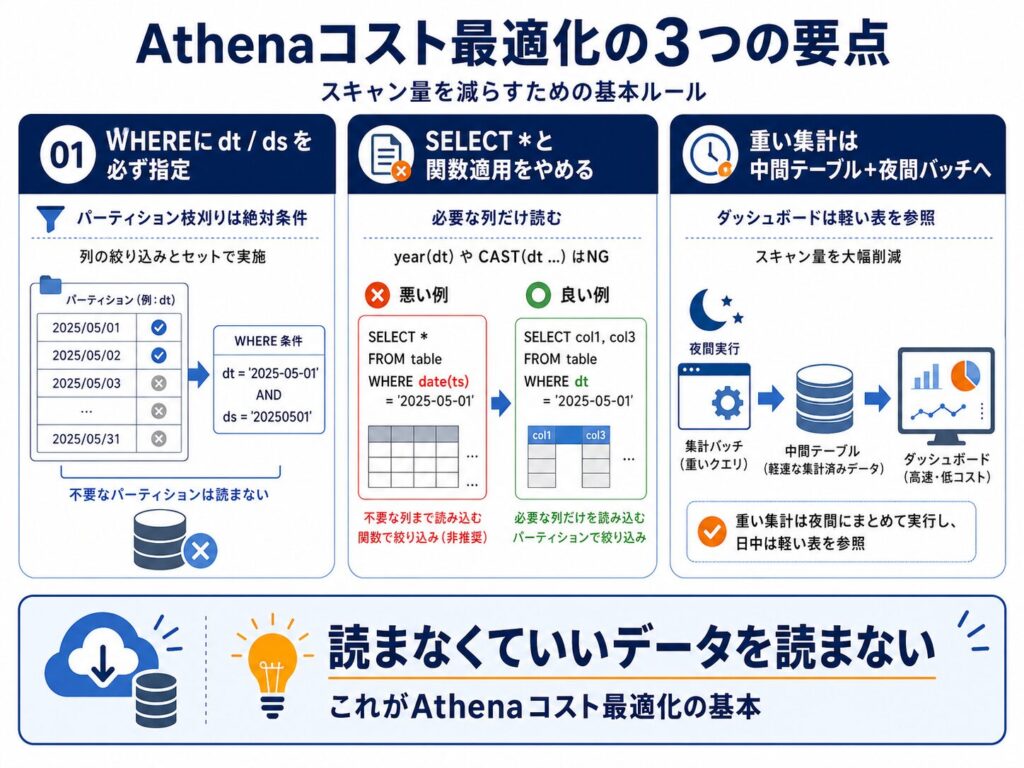
01 WHEREに dt/ds を必ず指定する
パーティション枝刈りは「すべきこと」ではなく「絶対条件」。列の絞り込みとセットで実施。
02 SELECT * とパーティション列への関数適用をやめる
year(dt)やCAST(dt AS varchar)を使った瞬間、フルスキャンに切り替わる。
03 重い集計は中間テーブル+夜間バッチに逃がす
ダッシュボードは中間テーブルを参照するだけにし、スキャン量を数百分の一に。
Athenaのコストは「習慣」で決まります。上記6点をチームで徹底するだけで、料金は半分以下、多くの場合90%以上の削減が現実的に達成できます。まずは自分のダッシュボード1本から、WHERE句を見直してみてください。
よくある質問
はい、AWS Athenaの標準料金はスキャンしたデータ量に応じた従量課金(2026年6月時点で5USD/TB)です。Lambda経由のフェデレーションクエリやProvisioned Capacityなどの例外はありますが、通常利用ではスキャン量=コストと考えて差し支えありません。クエリが速く終わっても、裏で数百GBを読んでいれば料金は跳ね上がります。
いいえ。パーティション枝刈り(行の絞り込み)と、列の絞り込みは別です。Parquetなどの列指向フォーマットでは、SELECTする列を絞ることで読み込み量が直接減ります。WHEREにdt/dsを指定しつつ、必要な列だけSELECTする——両方を実施するのが正解です。
「中間テーブル+夜間バッチ」のパターンに切り替えるのが最も効果的です。夜間にCTASで集計結果をsales.monthly_sales_summary等に保存し、BIツールのダッシュボードはその中間テーブルを参照するだけにします。同じ重いJOINを毎朝実行し続けるより、スキャン量・実行時間ともに桁違いに減ります。
ダメです。year(dt)やCAST(dt AS varchar)を使った瞬間、Athenaのオプティマイザはパーティション枝刈りを諦め、フルスキャンに切り替わります。dt BETWEEN date ‘2026-05-01’ AND date ‘2026-05-31’のように、パーティション列をそのまま範囲比較する書き方に置き換えてください。
EXPLAINで論理プランは確認できますが、正確なバイト数はわかりません。現実的には、まずLIMIT付きで1回実行し、Athenaクエリ履歴の「Data scanned (MB)」で実測値を確認する方法が確実です。月次でスキャン量TOP10のクエリを洗い出し、削減ターゲットを決める運用も有効です。
dtは日次パーティション(毎日の生ログ)で、直近の詳細分析に向きます。dsは断面パーティション(月初・週次など)で、期間比較やトレンド分析に向きます。テーブル定義で「日次なのか断面なのか」を確認し、意図と違う列でWHEREを書くと、無駄なスキャンや0件ヒットの原因になります。
下がります。CSVのままS3に置いてAthenaで読むのは、最もコストが膨らみやすいパターンです。Parquet形式・パーティション化・圧縮(Snappy/Zstd)で保管すると、同じクエリでもスキャン量が大きく減ります。中間テーブル作成時もWITH (format = ‘PARQUET’)を指定するのが定石です。
①WHEREにdt/ds必須のルールを共有、②探索クエリはLIMIT必須、③重い集計は中間テーブル化——この3点をチーム規約にするのが第一歩です。加えてAthena Workgroupでbytes_scanned_cutoff_per_query(1クエリのスキャン上限)を設定し、CloudWatchアラームで月額コストの閾値を監視すると、無自覚なフルスキャンを防げます。
