
「新機能を入れて以来、解約率は改善している気がするが、本当にその機能のおかげなのか自信が持てない」
「ABテストを実施したいが、技術的・倫理的・運用上の制約で、すべての利用者に同じ条件で配信せざるを得ない」
――こうした悩みは、サブスクリプションやSaaSの現場で日常的に発生しています。
ABテストはマーケティング・プロダクト施策の効果検証における王道ですが、現実にはABテストを実施できない場面が数多く存在します。たとえば、
- UI改善が全ユーザーに一斉展開される場合、特定の利用者だけに新機能を提供することが契約上難しい場合
- 過去にすでに展開済みの施策を遡って評価したい場合
などです。
このようなときに有効なアプローチの一つが、傾向スコアマッチング(Propensity Score Matching、以下PSM)です。
※マーケでよく使うPSM(価格感度測定)とは別物です
本記事では、私たちが実際に毎月運用しているPSM分析の中身を、初心者の方にもわかるように噛み砕いて紹介します。
データ分析に興味はあるけれど一歩踏み出せない全ての方の背中を押すきっかけになれば幸いです。
本記事のターゲット
- データ分析に興味があるが統計手法に苦手意識がある方
- PSM(傾向スコアマッチング)の月次運用がどんな仕事か知りたい方
- 施策の「本当の効果」を測りたい現場担当者の方
そもそもPSMとは?
なぜ単純比較ではダメなのか
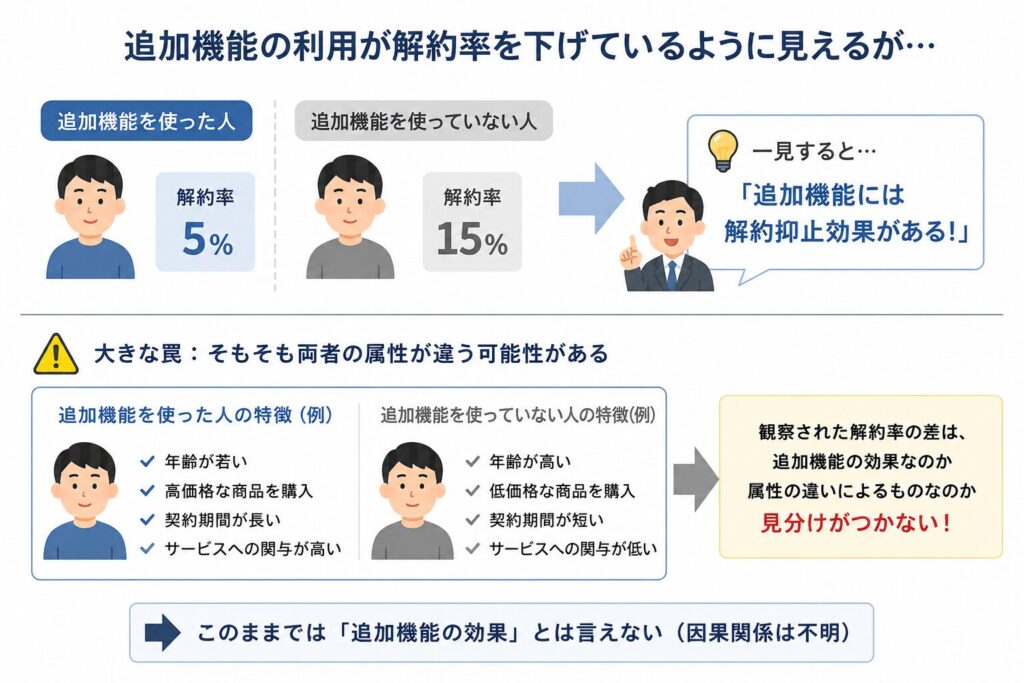
ある会員制サービスで、特定の追加機能を使ったお客様と使っていないお客様の解約率を比較したい、というケースを考えてみましょう。
単純にそれぞれの解約率を計算し、「追加機能の利用者の方が解約率が低い」という結果が出たとします。
一見「追加機能には解約抑止効果がある!」と言いたくなりますが、ここに大きな罠が潜んでいます。
そもそも追加機能を使う人と使わない人では、年齢・性別・購入商品・契約のきっかけなどの属性が全く違う可能性が高いのです。
「もともと熱心なお客様ほど追加機能を使う傾向があり、もともと熱心だから解約しにくい」という可能性が排除できません。
つまり、観察された差が追加機能の効果なのか、それとも属性の違いから来ているのか、見分けがつかないわけです。
PSMの基本的な考え方
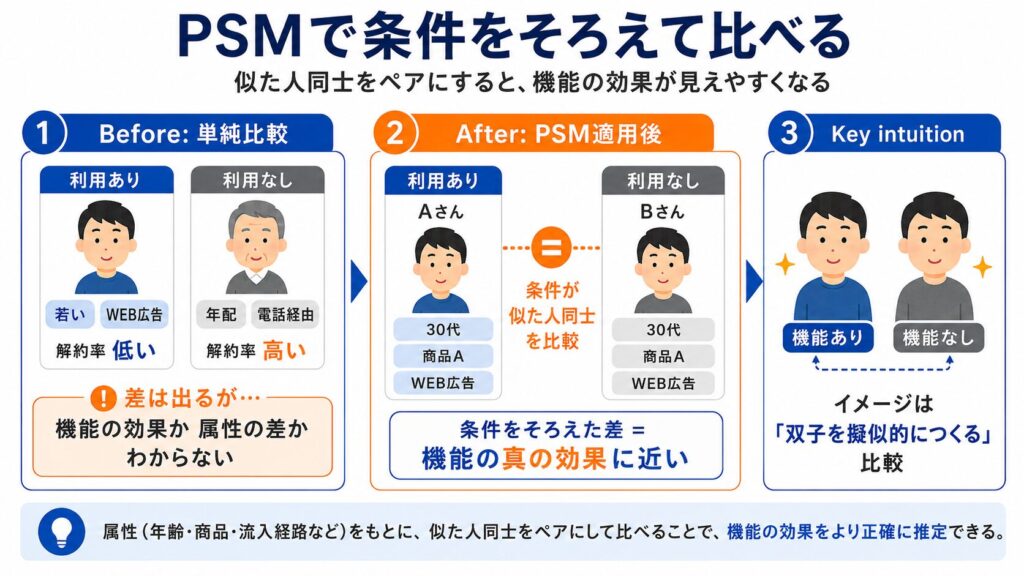
PSMは、この問題を「条件が似た人同士をペアにして比較する」という発想で解決します。
PSMを実施する前では以下のような状況が生まれ、解約率に差が出るが機能の効果か属性の差なのかの区別が困難です。
- 利用あり: 若い・WEB広告経由の人が多い → 解約率が低い
- 利用なし: 年配・電話経由の人が多い → 解約率が高い
一方PSMを実施することで、以下のように利用あり・利用なしから属性差を揃えたサンプルを抽出マッチングさせることで、機能の真の効果を推定します。
- 利用あり: 30代・商品Aを購入・WEB広告のAさん
- 利用なし: 30代・商品Aを購入・WEB広告のBさん(属性が似た人を選ぶ)
イメージとしては「双子のお客様を擬似的に作り出して、片方だけ機能を使った場合の差を見る」感覚に近いです。
PSMが調整できるのはデータに含まれる(観測された)属性だけです。
データに乗りにくい未観測要因が存在する場合、PSMでは消せない可能性があります。
「PSMは観測変数の偏りは補正できるが、未観測の交絡は残る(だから万能の魔法ではない)」という点は認識しておく必要があります
データから見る月次PSM運用の実態
運用の全体像
ここからは実際に私たちが回している月次運用の中身を見ていきます。
私たちの現場では、機能リリースや改善が月次で行われることが多いため、「定期契約初期の1〜3ヶ月の機能利用が解約抑止につながっているのか」を定期契約各月で検証していきたいと考えました。
例えば2025年8月に新機能をリリースしたとします。
その効果は定期契約開始が2025年9月以降の行について反映されるだろうというモニタリングの方法になります。
毎月初の第1営業日に、前月末までの最新データを参照する形で以下のフローを実行しています。
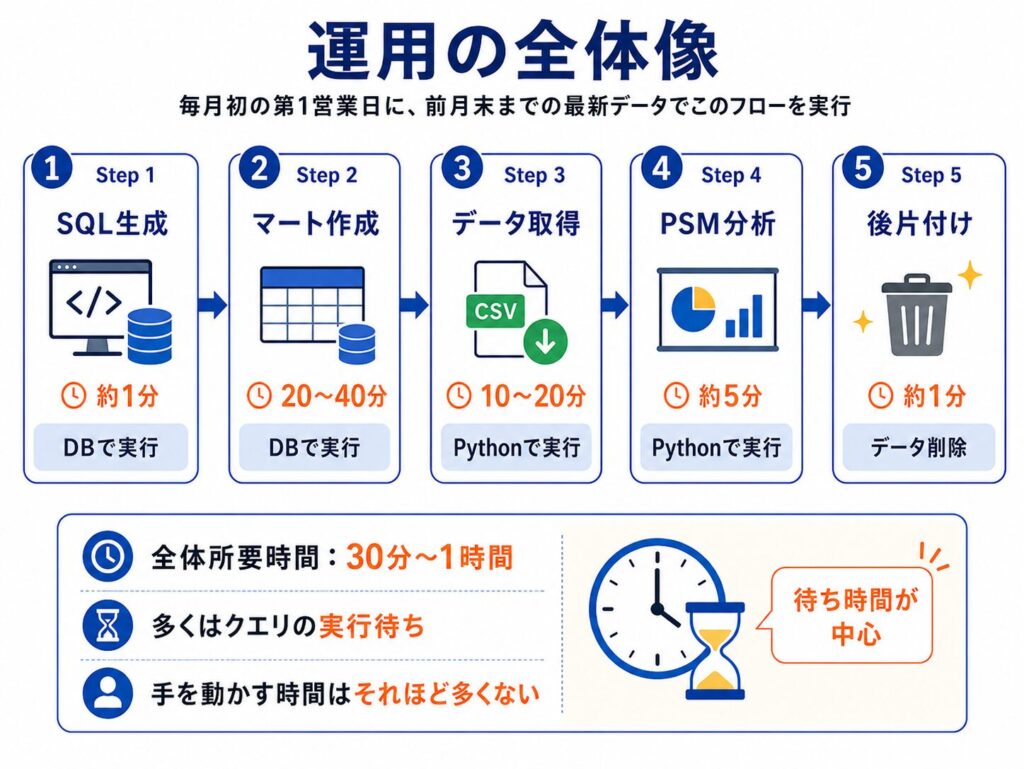
全体の所要時間は約30分〜1時間。そのうち大半は「クエリの実行待ち」なので、実は手を動かす時間はそれほど多くありません。
ステップ別の作業内訳
それでは各ステップで何をしているのか、もう少し詳しく見ていきましょう。
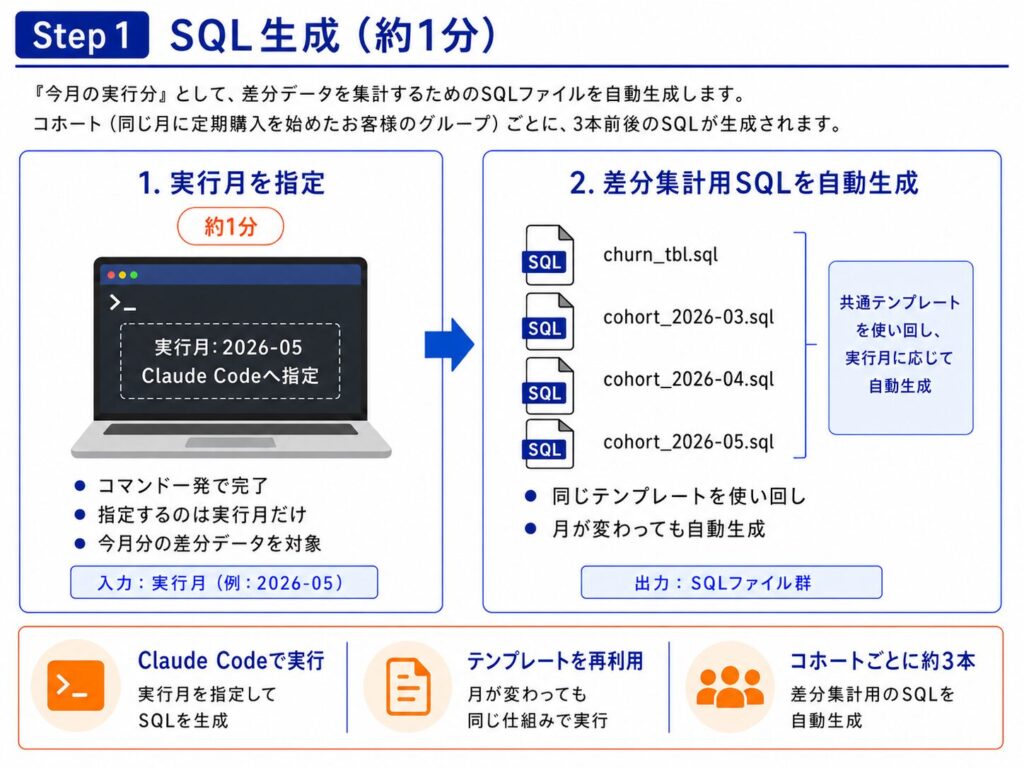
Step 1: SQL生成(約1分)
「今月の実行分」として、差分データを集計するためのSQLファイルを自動生成します。コホート(同じ月に定期購入を始めたお客様のグループ)ごとに3本前後のSQLが生まれます。
ここはコマンド一発で完了する工程で、私はClaude Codeへ「実行月(例: 2026-05)」を指定するだけの仕様にしています。月が変わっても同じテンプレートを使い回せるよう、SQLは自動生成される仕組みになっています。
Step 2: マート作成(20〜40分)
生成されたSQLをデータベースで順番に実行し、分析用のテーブル(マート)を作っていきます。具体的には以下の流れです。解約判定用テーブルとして、顧客識別用IDと定期購入開始月ごとの解約日付を記録。解約・機能利用コホートマートとして、顧客識別用IDと定期購入開始月ごとの顧客属性・nヶ月(1~3)ごとの解約状況・機能利用状況を記録します。
1. 解約判定用のテーブルを作成(約1分)
2. 解約・機能利用コホートマートのマートを順番に作成(約30分)
待ち時間が長いので、この間にコーヒーを淹れたり別作業を進めたりするのが私のスタイルです。
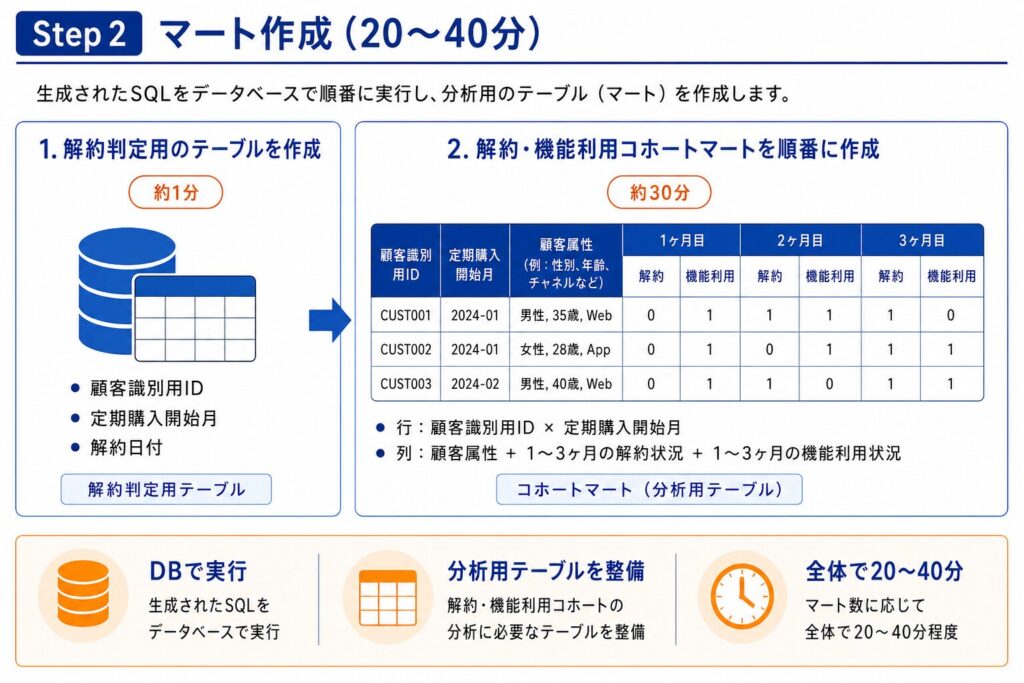
Step 3: データ取得(10〜20分)
Pythonコードを使い、以後のPSM分析が効率的に進むように、作成したマートをCSV形式で出力します。
ここで取り出すのは個人情報を含む場合があるため、後ほど必ず削除する一時ファイルとして扱います。
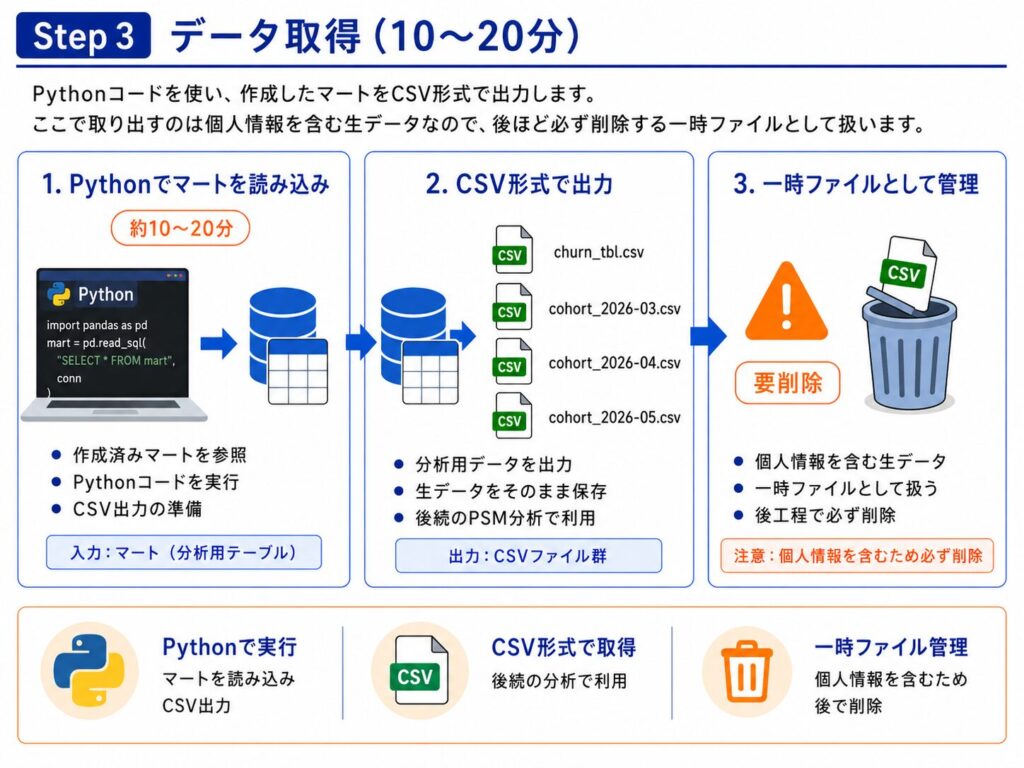
Step 4: PSM分析 + Excel出力(約5分)
ここが本丸の工程です。Pythonスクリプトが内部で以下を実行しています。
- ロジスティック回帰で「対象機能を使う確率(傾向スコア)」を推定
- スコアが近い利用あり・なしのペアを1対1でマッチング(非復元最近傍マッチング、caliper(ペアと認める許容差) = 0.2×SD)
- マッチングできたペア同士で解約率を比較
- 結果をExcelに集計
caliperは論文内でも言及されている標準的な設定である0.2SDを採用することで現場合意しました。
出力されるExcelには「月次解約率」「PSM効果サマリ」「実行メタデータ」の3シートが含まれ、報告会ではそのまま画面共有して議論できる形になっています。
Step 5: 後片付け(約1分)
最後に一時データ(個別レコードを含むCSV)を削除します。これは個人情報保護ポリシーで義務化されている企業も多いため、省略せずに必ず実行しましょう。
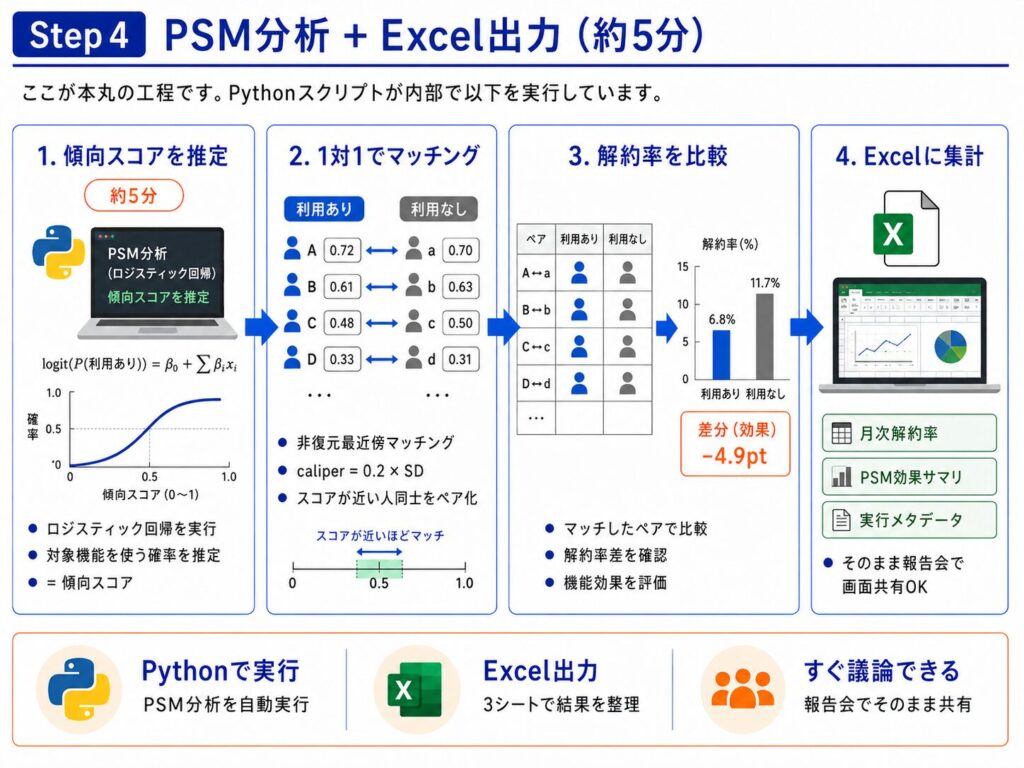
出力Excelの読み解き方
実際にExcelを開いたとき、最初に見るべきポイントを整理しておきましょう。
マッチ率:80%以上が望ましい
利用者と非利用者のうち、何%が「似た属性のペア」を見つけられたかを示す指標です。
50%を下回ると経営としては判断が難しいと考え、私の会社では80%で運用しています。
80%を下回る場合、比較の信頼性が大きく落ちるため、この時点で「データに偏りがありすぎる」という前提で数値を見る、もしくは「特徴量の見直し」「caliperの緩和(0.2→0.5)」などの対応で対処することが多いです。
PSM後_効果(pt):正の値なら機能の効果あり
「対象機能を使わなかったお客様の解約率」から「使ったお客様の解約率」を引いた値(パーセントポイント)です。例えば「+5pt」なら、機能の利用によって5%ポイント分の解約抑止効果があると解釈できます。より厳密に判断したい場合は、有意差検定も実施すると良いでしょう。
マッチ率が低くなってしまうことがあります。
これは利用者と非利用者の属性差が大きすぎる場合に発生します。例えば「利用者の大半が30代女性で、非利用者の大半が60代男性」のように偏っていると、似たペアが見つけられません。この場合はcaliperを緩める、特徴量を絞るなどの調整が必要になります。
まとめ
データ分析の運用業務というと「専門知識が必要で難しそう」というイメージがあるかもしれませんが、PSM月次運用の実態を踏まえて、運用を成功させるポイントを整理しておきます。
手順書と自動化に頼り切る
毎月手作業でSQLを書く必要はありません。「実行月」を指定するだけでSQLが自動生成され、PSMの計算も自動で走ります。重要なのは「自分が統計を理解しているか」ではなく、「手順書通りに進められるか」「異常時に正しく止まれるか」です。
待ち時間を有効活用する
実行時間の大半(30分〜1時間)はクエリ待ちです。実行投げたら別作業に移り、完了通知で戻ってくる、というスタイルで運用すれば、月次運用全体で実際に手を動かす時間は10〜15分程度に圧縮できます。
決して実行開始から完了まで実行画面を見つめることはやめてください。
異常値(マッチ率・N数)を見る習慣をつける
PSMは「動いた」だけでは不十分で、「マッチ率80%以上」「各コホートN数十分」といった健全性の指標を必ず確認します。マッチ率が低いまま結果を共有してしまうと、事業判断をミスリードしてしまうため、せっかくのPSMの意味がなくなってしまいます。
PSMは難しそうに見えますが、月次運用に落とし込んでしまえば「データ更新のルーチンワーク」に過ぎません。
ぜひ興味を持った方は、ご自身の現場で「単純比較になっている分析」がないか棚卸ししてみてください。
意外と多くの場面でPSMが役立つはずです。
よくある質問
傾向スコアマッチング(Propensity Score Matching)とは、施策を受けた人と受けていない人の属性(年齢・性別・プランなど)を統計的に揃えた上で、施策の純粋な効果を推定する因果推論の手法です。属性が似た人同士をペアにして比較することで、「もともと条件が違う人を比べてしまう」交絡バイアスを取り除きます。
できます。全ユーザーに一斉ロールアウトされた施策や、すでに実施済みの施策など、ランダムな割り付けができない場合でも、PSMをはじめとする因果推論手法を使えば観測データから効果を推定できます。本記事ではサブスクサービスの新機能を題材に、ABテストなしで継続率への効果を測定する方法を解説しています。
単純比較は誤った結論を招きやすいため注意が必要です。たとえば新機能の利用者が若年層に偏っていると、「もともと解約しにくい人が使っている」だけで効果が大きく見えてしまいます。本記事の事例でも、単純比較では+20ptあった差が、PSMで属性を揃えると+15ptに縮小し、約25%が交絡バイアスだったことが分かりました。
交絡バイアスとは、施策の有無と結果の両方に影響を与える第三の要因(交絡因子)によって、見かけ上の効果が歪んでしまう現象です。年齢・性別・契約プランなどが代表例です。PSMはこうした交絡因子を共変量として揃えることで、施策そのものの純粋な効果を取り出します。
「施策を使うかどうか」と「結果(継続率など)」の両方に影響しそうな変数を、業務知識をもとに選びます。サブスクサービスなら、年代・性別・加入プラン・獲得チャネル・初月の利用頻度・受信許諾状況などが一般的です。共変量は多すぎるとマッチング率が下がり、少なすぎると交絡が残るため、バランス感覚が重要です。
マッチ率とSMD(標準化差)の2つで確認します。マッチ率は80%以上が目標で、50%を下回ると対象群と対照群の重なりが少ないサインです。SMDは各共変量で0.1未満に抑えられているかが目安となります。ただしSMDだけでなく、実際の数値の差(例:年齢差が何歳か)も併せて評価することが大切です。
必要ありません。本記事では大規模クラウドインフラを使わず、無料のローカルデータベース(SQLiteやPostgreSQL)に顧客データを格納し、Pythonの無料ライブラリ(psmpy・scikit-learnなど)でPSMを実行する構成を紹介しています。クラウド認証も不要で、手元のPCだけで再現・検証できます。
PSMが揃えられるのは「観測できた共変量」だけで、データに含まれない未観測の要因までは除けません。この弱点を補うために、IPW(逆確率重み付け)やRosenbaumの感度分析を組み合わせ、未観測交絡への頑健性をクロスチェックすることが推奨されます。
